Schon im November letzten Jahres bin ich auf ein Nachricht1 gestoßen, in der es hieß eine US-amerikanische Professorin hätte festgestellt, dass die Werbung bei und von Google bei der Suche nach Personen rassistische Vorurteile bedienen würden, nämlich das nicht-weiße häufiger vorbestraft sind. Letzte Woche wurde ich dann wieder darauf aufmerksam, die vollständig Studie2 dazu wurde bereits im Januar veröffentlicht wurde.
Es geht darum, dass oben genannte Professorin (mit dem Namen Latanya Sweeney selbst betroffen) darauf aufmerksam wurde, dass, wenn man nach Vorname-Nachname Kombinationen bei Google und anderen Seiten sucht, verstärkt Werbung auftaucht, die Informationen aus öffentlichen Quellen über den/die Gesuchte anbieten. Dabei war es augenscheinlich so, dass bei solchen Namen die in den USA als black-identifying wahrgenommen werden, mit den man also People of Color (PoC) assoziert, mit dem Werbetext „$NAME arrested?“ für den Dienst geworben wurde, während bei nicht eindeutigen Namen eher so etwas wie „We found $Name“ an der Seite stand. Unabhängig von der konkreten Person, nach der gesucht wurde im Anzeigentext schon etwas über die Person, nämlich deren vermeintlich krimineller Background, impliziert.
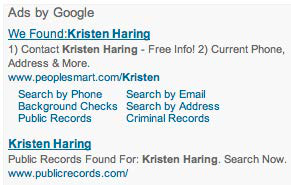
Werbung ohne Hinweis auf vermeintliche Inhaftierungen
Werbung mit Hinweis auf vermeintliche Inhaftierung (Beide Bilder aus [Sweeney 2013])
Aber einen Schritt zurück: In den USA ist es nicht unüblich, dass es öffentliche Verzeichnisse mit den Namen und Bildern von Kriminellen gibt. In Florida z.B. ist der Offender Search schon seit 2002 online. Da kann man relativ einfach Informationen aus mehreren Datenbanken abrufen, etwa über alle Inhaftierten und Flüchtigen, aber auch bereits Entlassene und solche unter Aufsicht werden dort gelistet. Schön durchsuchbar nach allem was auch in der Polizeiakte steht: Name, Geburtsdatum Körpergröße, Gewicht, Augen- und Haarfarbe und natürlich das Verbrechen für das jemand verurteilt wurde. Diese Daten stehen für die „öffentliche Sicherheit“ frei im Internet. Was im deutschsprachigen Raum als „Internetpranger“ für unseriös erklärt wird und sich selbst auf der Ebene von Gastronomiebetrieben nicht durchsetzen lässt, ist in den USA (und anderen Ländern) also durchaus üblich und wird regelmäßig ausgebaut, auch wenn dort wesentlich mehr Menschen in den Knästen sitzen und verurteilt werden. Damit das nicht so amerika-kulturpessimistisch klingt: Auf der anderen Seite ist die Antidiskriminierungsgesetzgebung in den USA schon wesentlich älter und auch die Praxis, wie etwa anonyme oder zumindest fotolose Bewerbungsverfahren, wesentlich weiter verbreitet. Natürlich heißt das wiederum auch nicht, dass es keinen Rassismus oder Diskriminierung von Ex-Häftlingen gibt.
Allerdings hat die Praxis in den USA auch aus der ‚Free All Data‘-Sicht noch Mängel: da die Datenbanken in Ländergesetzen geregelt werden gibt es keine zentrale, öffentliche, Datenbank für die gesamten USA. Und da kommen nun die kommerziellen Anbieter ins Spiel, die diese Lücke schließen. Mehrere Anbieter haben die dezentralen Datenbanken kopiert und zentral zusammengeführt. Allen voran instantcheckmate.com.
Technisch ist das Zusammenführen kein besonders großes Problem, schwieriger ist es wohl eher mit der Datensammlung Geld zu machen. Nicht unüblich ist da das Freemium Model. Zu Werbezwecken wird mit einer einfachen, kostenlosen Suche gelockt, wer aber mehr Wissen will muss einen Premium Account abschließen3. Instantcheckmate wirbt also damit eine Akte über sehr viele Personen zu haben die aus verschiedenen Quellen zusammengeführt ist (da gibt es ja z.B. noch öffentliche Wähler*innenverzeichnisse oder Wahlkampfspender*innenlisten usw.). Die Seite bietet also nicht nur Akten über Verurteile Straftäter*innen an, sondern über alle die im Internet auf irgendeiner öffentlichen Liste stehen.
Und um den Dienst selber zu bewerben benutzen sie Google AdWords. Also das, womit Google am meisten Geld verdient: Sie stellen bei AdWords Suchbegriffe ein bei denen Sie an der Seite als Anzeigenvorschlag erscheinen wollen. Neben Google können auch andere Seitenanbieter sich diese Werbeleisten in ihre Seite einbauen. In dem Fall teilt sich Google die Einnahmen mit der Seite. Im Artikel von Sweeney wird vor allem reuters.com als Testseite verwendet.
Jetzt genauer zu der Studie: Sweeney formulierte einen Anfangsverdacht, dass die Werbeanzeigen unterschiedliche Teasertexte verwenden abhängig von der vermeintlichen Hautfarbe der Person. Dabei würde bei Namen, die mit PoC assoziiert werden, wesentlich häufiger ein direkter Hinweis auf einen Registrierung als Kriminelle*r vorliegen als bei vermeintlich Weißen. In Kurz: Ihre Versuche haben das Bestätigt. Für black-identifiying names enthielten 60% den Begriff „arrested“. Bei white-identifiying names 48% ([Sweeney 2013 S. 22]).
![Original Bildunterschrift: "Distributions of Instant Checkmate ads having theword “arrest” or not (“neutral”) appearing on Google.com." [Sweeney 2013] Sortiert nach Name](http://blog.pilpul.me/files/2013/05/sweeny4.png)
Original Bildunterschrift: „Distributions of
Instant Checkmate ads having the word “arrest” or not (“neutral”) appearing on Google.com.“ [Sweeney 2013] Sortiert nach Name
Interessant ist jetzt natürlich die Frage der Verantwortung. Offensichtlich hat instantcheckmate.com mehrere „Templates“ bei Google hinterlegt; also wenn ein Name gesucht wird, wird der in Kombation mit „Located: $NAME“, „We found: $NAME“ und eben auch „$NAME was arrested?“ als Werbeanzeige angezeigt. Natürlich haben sowohl Google als auch Instantcheckmate dem Vorwurf widersprochen die unterschiedliche prozentuale Ausprägung der tendenziösen Anzeigen wäre mit Absicht herbeigeführt.
Viel mehr scheint das Problem ähnlich dem bei der Autovervollständigungsdebatte zu sein. Während das oft zu witzigen Vorschlägen führt, hatte Bettina Wulff dagegen und darüber geklagt, dass als erster Ergänzungsvorschlag für ihren Namen bei der Google Suche immer irgendwas mit Prostitution auftaucht. Google hatte argumentiert, dass die Vorschläge darauf beruhen, welche Begriffe die Nutzer*innen in Kombination suchen. Es sich also nur um aggregierte Informationen handelt und keine weitere Entscheidung oder Intelligenz bei Google dazu beitrage, man also unschuldig sei an dem was dabei rauskäme. Zuletzt wurde Google trotzdem dazu verurteilt solche tendenziösen Vorschläge zu unterbinden, sobald sie darüber informiert würden. Ähnlich verhält es sich vermutlich bei den Anzeigen. Da Google mitverdient wenn auf eine Anzeige geklickt wird, ist es durchaus vorstellbar, dass solche Anzeigen häufiger geschaltet werden, auf die Surfer*innen auch tatsächlich geklickt haben. Und wenn Links mit vermeintlichen Hinweisen auf ‚criminal records‘ mehr Klicks hervorbringen als einfache ‚we found‘ Links, wird ersterer häufiger angezeigt. Nicht nur Sex-Sells sondern auch Crime-Sales und Google versteht sich nur als Aggregator von Vorurteilen der Schwarmintelligenz.
Tatsächlich sind die Anzeigen mittlerweile wohl aber so nicht mehr aufzufinden bzw. die Ergebnisse nicht mehr mit aktuellen Daten zu verifizieren. Instantcheckmate macht es jetzt wie die übrigen Anbieter von solchen Datenbanken und verzichtet einfach komplett auf so tendenziöse Werbetexte.
Vielleicht sollte man sich auch bei Google mal verstärkt mit ‚Discrimination-aware data mining‘4 auseinander setzen, auf das Sweeney auch hinweist. Ich werds‘ mir nochmal zu Gemüte führen.
- die Seite ist mittlerweile offline [↩]
- Sweeney, Latanya. 2013. „Discrimination in Online Ad Delivery“. SSRN Scholarly Paper ID 2208240. Rochester, NY: Social Science Research Network. [↩]
- bei instantcheckmate macht das ~20$ im Monat [↩]
- Pedreshi, Dino, Salvatore Ruggieri, und Franco Turini. 2008. „Discrimination-aware data mining“. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, 560–568. KDD ’08. New York, NY, USA: ACM. [↩]
Schreibe einen Kommentar