Aus der Kategorie „Was sich aus Social Media nicht alles ‚vorhersagen‘ lässt“ stell‘ ich heute eine Studie vor, bei der Schäden, die durch Naturkatastropen verursacht wurden, anhand von Twitter vorhergesagt werden sollen. Anhand der Studie lassen sich auch gut die Grenzen der Big Data Analyse von Social Media Daten aufzeigen.
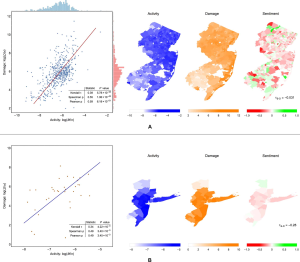
Die relativ knappe Korrelation von nur 0.56 wird von den Autoren dennoch als positiver Zusammenhang gewertet. ((Als Fußnote taugt noch der Hinweis auf den methodisch eher ungenauen Umgang mit den Korrelationswerten, da werden einfach drei Typen von Korrelationen berechnet und dann der beste genommen, ohne sich zu Fragen warum die unterschiedliche Ergebnisse liefern))
In der Studie ((Kryvasheyeu, Yury, Haohui Chen, Nick Obradovich, Esteban Moro, Pascal Van Hentenryck, James Fowler, und Manuel Cebrian. 2016. „Rapid assessment of disaster damage using social media activity“. Science Advances 2 (3). doi:10.1126/sciadv.1500779.)) konnten die Autoren einen statistischen Zusammenhang zwischen der Pro-Kopf Aufkommen von Tweets und dem Pro-Kopf Schaden nach Naturkatastrophen (in den USA) nachweisen.
Mehr Tweets = mehr Schaden
Wesentlich Erkenntnis der Analyse ist, dass die Anzahl der Tweets an sich, und die Anzahl der Tweets die sich auf das Ereignis beziehen, geringer ist je weiter sich der*die Tweetende von dem Ereignis weg befindet. Bezogen auf das Beispiel Hurriance Sandy können die Forscher*innen nachweisen, dass mehr Leute über Sandy Twittern je näher sie an der (erwarteten) Route lagen. Voraussetzung für eine solche Analyse ist natürlich, dass in allen betroffenen Regionen ein Internetzugang vorhanden ist und bleibt.
Diese Erkenntnis ist allerdings nicht der eigentliche Punkte des Artikels. Viel mehr geht es darum den Schaden, den eine Naturkatastrophe angerichtet hat, auf die Twitter Intensität zu beziehen. Dabei stellen sie fest, dass an den Orten, an denen mehr Schaden entstanden ist, auch nach Abzug des Unwetters noch häufiger zu dem Thema getwittert wird. Sie vergleichen die berechneten Zusammenhänge dann mit den Berechnungen des Katastrophenschutzes und finden ihr Modell näher an der Realität.
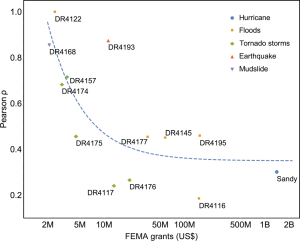
Weitere Einschränkung: Die Berechnung funktioniert vor allen Dingen bei Naturkatastropen mit geringem Ausmaß.
Mit Vorhersage, wie es in dem Ankündigungsartikel zu der Studie getitelt wird, hat das allerdings wenig zu tun. Schließlich wird der Schaden nicht vor dem Unwetter berechnet, sondern erst, nachdem es eingetreten ist. Möglicherweise ist die Beobachtung von Twitter da schneller als auf Anrufe von Betroffenen zu warten, aber überzeugt bin ich nicht.
Interessant ist eher der Aufwand der getrieben werden muss um die Twitter Daten überhaupt nutzbar zu machen. Dafür müssen die Tweets erst über die Einwohnerdichte normalisiert, Korrekturen an der Gelocation manuell vorgenommen und rausgefunden werden welche Akteure (Nachrichtenagenturen) und Tweet-Type (Re-Tweets) man besser nicht mit einbezieht.
Zitiert aber nicht gelesen
Die Autoren verweisen im Selbstkritikabschnitt auf einen Artikel ((Lazer, David, Ryan Kennedy, Gary King, und Alessandro Vespignani. 2014. „The parable of Google Flu: traps in big data analysis“. Science 343 (14 March).))) aus 2014, der mir bisher unbekannt war. Darin wird der Misserfolge von Google Flu Trends zum Anlass genommen Kritik an dem Big Data Hype und den, auf Social Media basierenden, Analysen zu äußern.
Zur Erinnerung: Google Flu Trends war angetreten mit der Idee Grippewellen anhand von Suchbegriffen vorherzusagen. Verglichen wurden die Vorhersagen mit den Berichten der amerikanischen Gesundheitsbehörde, die ihre Daten (viel mühsamer, aber dafür korrekt) vor Ort sammelt. Zwar lag GFT von der Tendenz her selten falsch, hat aber die Ausmaße der Grippewellen, auch nach zwei Verbesserungen, dauerhaft wesentlich zu stark eingeschätzt. Die Autor*innen nutzen das Versagen von GFT, um daran zwei Punkte deutlich zu machen.
Big Data Hybris
Sie stellen fest, dass es zum Big Data Hype gehört zu glauben, dass mehr Daten ein Problem lösen können, dem mit Modellierung nicht beizukommen ist. Dabei würden grundsätzliche Arbeitsschritte des Data Mining, wie die Datenaufbereitung, hinten angestellt, auch wenn sie, sowohl bei GFT als auch bei der Hurricane-Schadensberechnung, absolut notwendig waren.
Algorithm Dynamics
Wesentlich schwerer wiegt das Problem, das sie als algorithm dynamics bezeichnen. Damit meinen sie, dass Social Media keine immer gleichen mechanischen Sensordaten erzeugt, sondern der Kontext der Datenerzeugung sich ständig ändert.
Auf der einen Seiten seien die User, deren Verhalten (Tweets oder eingetippte Suchworte) nicht nur mit dem Problem zusammenhängen, das untersucht wird, sondern auch von so etwas wie Medienaufmerksamkeit (z.B. für die Vogel- oder Schweingrippe) abhängig sind.
Auf der andern Seite seien auch die Betreiber*innen der Netzwerke oder Suchmaschinen dafür verantwortlich, dass sich die Datenqualität ständig ändert. Googles würde etwa ständig Änderungen und Verbesserungen an seiner Suchmaschine durchführen, wodurch sich auch das Verhalten der Nutzer*innen ändere. Wenn etwa durch die Autovervollständigung oder die Einbettung von Suchergebnissen Begriffe anders oder gar nicht mehr eingegeben werden müssten, ändert dies grundsätzlich den Datensatz mit dem GFT arbeiten kann.
Lazar und Kollegen schließen mit einem Hinweis auf Dinge, die man bei Big Data Analyse von Social Media berücksichtigen sollten. Darunter fällt auch „Use Big Data to Understand the Unknown“. Statt mit Big Data Dinge (besser) machen zu wollen also es bisherige Modelle könne, sollte man sich um bisher ungelöst Probleme kümmern für die Big Data neue Ansätze liefern könnte. Genau diesen Fehler haben Kryvasheyeu und Co begangen mit dem Versuch Modelle, die bereits bestehen, mit Big Data in Konkurrenz zu setzen.
Schreibe einen Kommentar