Es sind immer wieder die kleinen Machbarkeitsstudien, die es groß in die Presse schaffen. Diesmal war es ein kurzer (ob das auch zu dem Erfolg beigetragen hat?) Artikel über die Möglichkeit durch Facebook-Likes die Persönlichkeiten der Nutzer_innen zu messen. Das Ergebnis wird zusammengefasst in Überschriften wie „Facebook knows you better than your own family members„, „Computers Know the Real You Better than Friends, Family„.
Our findings highlight that people’s personalities can be predicted automatically and without involving human social-cognitive skills.
Die Autor_innen1 folgern aus ihrer Studie, dass die Bestimmung von Eigenschaften einer Persönlichkeit durch einen Algorithmus genauso gut erfolgen kann wie durch menschliche Expertise. Da es um Vorhersagen geht, wollte ich mir das mal genauer anschauen.
In der Studie wurden Daten einer Facebook-App genutzt bei der 86 660 Facebook-Nutzer_innen haben einen Persönlichkeitstest gemacht haben, der aus 100 Fragen besteht. Der standardisierte Fragebogen wird in der Psychologie genutzt, um die „Big Five“ genannten Persönlichkeitsmerkmale durch Selbsteinschätzung zu messen: Offenheit für Erfahrung, Gewissenhaftigkeit, Extraversion, Verträglichkeit und Neurotizismus. Für die Studie wurden diese Daten verglichen (korreliert) mit den Facebook-Profilen der Nutzer_innen, genauer mit den Dingen die sie „geliked“ hatten.
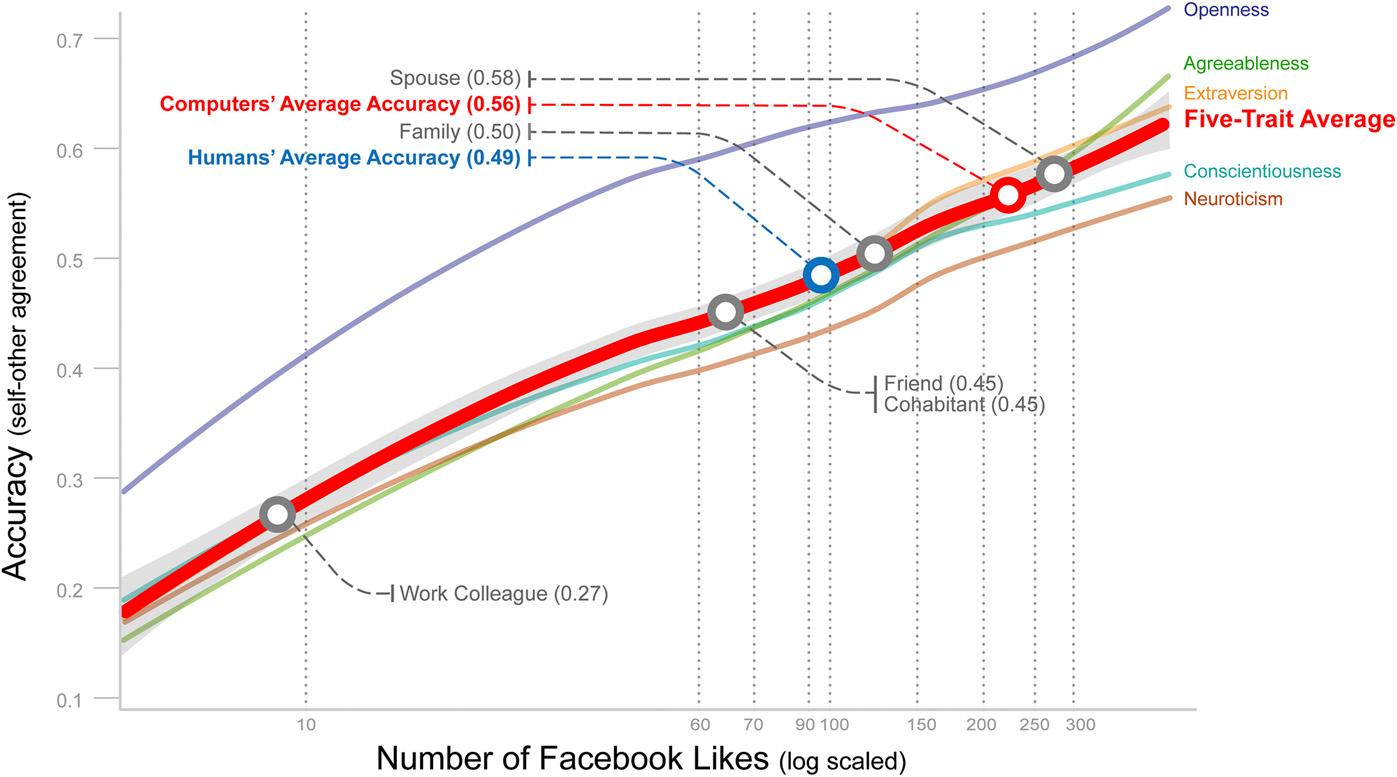
Der Graph zeigt wie gut der Alogrithmus bei den verschiedenen Merkmalen ist (Y-Achse) in Abhängigkeit von der Anzahl der Likes (X-Achse). Zudem sind Vergleichwerte der menschlichen Einschätzer_innen eingetragen.
Der Hauptteil der Studie bezieht sich dann auf die Möglichkeit die Daten zu benutzen, um mit den Korrelationsdaten die Persönlichkeitsmerkmale von Personen anhand ihrer Facebook Likes zu berechnen. Das Ergebnis wird verglichen damit, wie gut Freund_innen, Kollegen oder Partner_innen in der Einschätzung sind. Dabei wurde auf 17 622 (von den ursprünglich fast 90 0002 ) Ergebnisse von Fragebögen zurück gegriffen bei denen diejenigen die den Test ausgefüllt hatten auch Freund_innen davon überzeugen könnten 10 elementigen3 Fragebogen über sie auszufüllen. Verglichen wird also die Selbsteinschätzung mit der Fremdeinschätzung. Gut ist, wenn beides übereinstimmt.
Andere zu bewerten funktioniert einfach nicht gut
Hier macht die Studie einen klugen argumentativen Trick. Tatsächlich funktioniert der Algorithmus zur Persönlichkeitsbewertung nämlich gar nicht besonders gut, und liefert überhaupt erst annehmbare Ergebnisse wenn mehr mehr als 100 Likes abgegeben wurden. Einer der Reviewer übersetzt in seinem Blog die Korrelationskoeffizienten so:
Wenn man sich selbst bei einem der Persönlichkeitsmerkmale oberhalb des Durchschnitts einsortiert zeigen die Daten, dass 74,5% der Fälle das die Freund_innen auch tun würden. Der Computeralgorithmus kann das zwar besser, aber trifft auch nur in 78% der Fälle die Selbsteinschätzung. Das heißt, wenn ich und 99 andere über mich selbst sagen würde ich bin freundlicher als der Durchschnitt (und wir würden annehmen, dass das „wahr“ ist), würden Freund_innen (über einen Fragebogen) in 25,5% der Fälle widersprechen (und damit „falsch“ liegen). Ein Computer der unsere Facebooklikes (die es in meinem Fall nicht gibt) beobachtet, würde läge in 22% der Fälle falsch. Das sind beides keine besonders überzeugenden Zahlen, aber dass beide (Freund_innen und Computer) nicht besonders gut sind, wird in der Studie nicht thematisiert, es geht nur darum wer nicht ganz so schlecht ist.
Wem es nützt?
Die Studie ist nun technisch4 sauber ausgeführt, und was mich tatsächlich mehr stört ist in welchen Kontext die Autor_innen ihre Studie stellen.
Automated, accurate, and cheap personality assessment tools could affect society in many ways: marketing messages could be tailored to users’ personalities; recruiters could better match candidates with jobs based on their personality; […] Furthermore, in the future, people might abandon their own psychological judgments and rely on computers when making important life decisions, such as choosing activities, career paths, or even romantic partners. It is possible that such data-driven decisions will improve people’s lives. (S. 4)
Die Visionen für den Nutzen automatischer Persönlichkeitstests „für die Gesellschaft“ sind folgende: Man kann es nutzen für Werbung, für Personalabteilungen, Produktpersonalisierung und zuletzt könnten Leute ja auch anfangen Lebensentscheidungen lieber nicht mehr auf Basis ihrer Erfahrung, sondern mit Tipps aus dem Computer treffen.
Einerseits find‘ ich es unbehaglich, dass die ersten Anwendungsfelder die den Autor_innen einfallen solche sind, bei denen nicht die Leute selbst entscheiden was mit ihren Daten passiert, sondern sie von anderen kapitalisiert werden. Und andererseits ist es genauso gruselig, dass die einzige Möglichkeit die ihnen einfällt, die tatsächlich den Leuten direkt einen Nutzen geben könnte, eine ist, bei der sie Verantwortung für ihr Leben an einen Automaten auslagern, der glaub sie (zu 78%) zu kennen.
Nur in einem Nachsatz wird dann erwähnt, dass manche Leute es vielleicht nicht so gut fänden, wenn so eine Technologie von Regierungen oder Werbenetzwerken eingesetzt würde, aber sie hoffen, dass sich (andere) Leute um solche Fragen kümmern. Ganz ohne Big Data und Facebook-Likes ist mein Einschätzung der Persönlichkeitsmerkmale der Autor_innen im Bereich „Verantwortungsbewusstsein“ am Ende ziemlich schlecht 🙂
- Youyou, Wu, Michal Kosinski, and David Stillwell (2015) Computer-Based Personality Judgments Are More Accurate than Those Made by Humans. Proceedings of the National Academy of Sciences. [↩]
- Über die ganze Studie werden die Zahlen eigentlich immer kleiner, am Ende können die meisten Aussagen eigentlich nur über knapp 2000 Fälle gemacht werden [↩]
- auf statistischer Ebene könnte man sicherlich schon kritisieren, dass sich hier ein leichter Gegner ausgesucht wurde, wenn die Ergebnisse eines 100 Fragen-Bogens mit dem eines 10-Fragen-Bogens verglichen werden [↩]
- Es mangelt auch einer Diskussion der Datenbasis. Tatsächlich sind die Ergebnisse ja auf einer eher homogenen Gruppe von Menschen angewendet worden, nämlich denen die Facebook benutzen und diese App. Das es sich dabei um eine Gruppe mit „besonderen“ Eigenschaften handelt zeigt sich nicht zu letzt daran, dass der Algorithmus vor allem bei „Openness“ so gut funktioniert, denn das fördert ja Facebook. [↩]
0 Kommentare
2 Pingbacks