Über einen Bericht zu den predictive policing Plänen in New York, bin ich auf die Software HunchLab gestoßen. Die, sowie die das darin implementierte Konzept des Risk Terrain Modeling hab‘ ich mir daraufhin etwas genauer angeschaut.
HunchLab hat gerade Version 2 seiner Software fertig gestellt und ist damit auf Expansionskurs. Während Version 1 bereits in Philadelphia und einigen anderen Städten getestet wurde ist Version zwei noch relativ neu und kann als Software as a Service (SaaS) online gebucht werden. Das Kernkonzept ist dasselbe wie bei anderen predictive policing Anwendungen.
“What we get is a risk map that shows where there are elevations of risk for tomorrow,“ Hunchlab Product Manager Jeremy Heffner technical.ly (2011)
Hinter HunchLab steht die Software Firma Azavea die, anders als die Macher von PredPol, in einem zugänglichen Dokument sehr detailliert auf die Funktionsweise und die dahinter liegenden Konzepte eingeht.
-
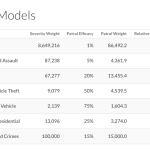
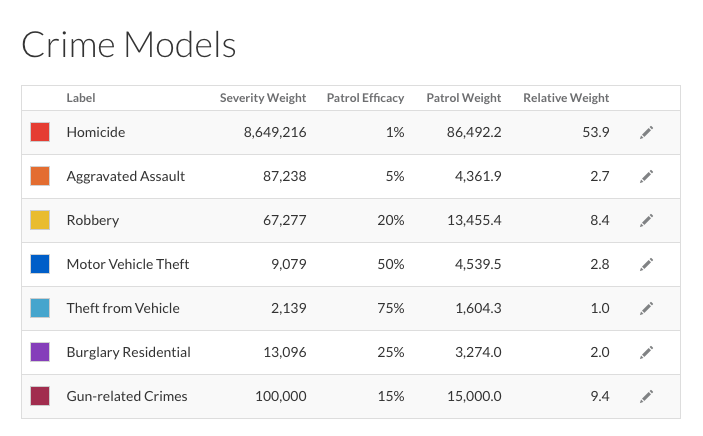
- In Hunchlab kann jemand mit höhrem Rang für jede Verbrechensart festlegen wie wichtig Streifen dabei sind.
-
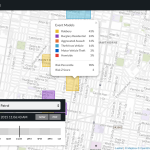
- Wie in alle ähnlichen Produkten werden für Bezirken von der Größe mehrerer Blöcke die Risikoquoten berechnet

-
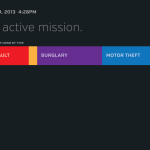
- Für die Streifen gibt es dann hübsche Übersichtanzeigen für ihre aktuelle „Mission“.
HunchLab
Wie die Screenshots zeigen funktioniert die Anwendung ähnlich dem was auch andere Predictive Policing Anwendungen können. Es gibt eine Analyst_innen-Ansicht und eine für die Streifenpolizist_innen. HunchLab hat scheinbar einiges in ein schickes UX-Design investiert und insbesondere die Ansicht für die Endnutzer_innen (drittes Bild) stark vereinfacht. Die Überschriften mit der „active mission“ sieht irgendwie nach dem Versuch einer Gamification aus, aber das kann auch an der Übersetzung liegen.
HunchLab wird als Software as a Service (SaaS) angeboten, d.h. man mietet die Software statt sie zu kaufen/lizensieren und selbst zu installieren. Sie läuft dann vollständig in der „Cloud“, bzw. im konkreten Fall auf Servern von Amazon. Dazu muss dann eine Anbindung der Polizeidatenbank an die Software bereit gestellt werden, so dass Kartenmaterial, aber auch Listen von angezeigten Straftaten übermittelt werden. Darüber hinaus ist es aus Sicht der Macher_innen auch sinnvoll, Adressen von bekannten Straftäter_innen einzubinden Für eine Anwendung in Deutschland ist das Tool also Datenschutzgründen nicht ohne weiteres einsetzbar, in den USA, wo solche Listen eh öffentlich zugänglich sind, ist das natürlich was anderes. Das die Daten in der Amazon Cloud allerdings nicht zwangsläufig sicher sind, hat sich erst gerade wieder einmal bestätigt.
Die Algorithmen
Zumindest was die dahinter liegenden Forschungsarbeiten angeht ist Azavea sehr offen. Sie beziehen sich auf Near Repeat Idee genauso wie das Risk Terrain Modeling und kombinieren beiden Konzepte mit einem Verfahren das sie Gradient Boosting nennen und und Entscheidungsbäume produziert (Dokument ab Folie 17). Beim Gradient Boosting handelt es sich um ein Verfahren des maschinellen Lernens, dessen Vorteil darin besteht, dass sich in der Ergebnisfunktion die ein Ereignis vorhersagen soll, noch ablesen lässt welche Faktoren wie Einfluss genommen haben. Viele andere Verfahren, wie neuronale Netze beim Deep Learning, erlauben dies häufig nicht, wodurch den Systemen immer eine gewisse Magie zugesprochen wird.
HunchLab setzt weniger auf diese Magie sondern schreibt selbst:
Software, after all, doesn’t prevent crime.
Auffällig ist, dass der Product Manager von HunchLab vorher unter anderem an der Rutgers University gearbeitet wo das Risk Terrain Modeling entwickelt und relativ monopolisiert erforscht wird.
Risk Terrain Modeling
Das Konzept des Risk Terrain Modeling unterscheidet sich etwas von dem der Near Repeats bei denen die Eintrittswahrscheinlichkeit eines Verbrechens von vorherigen Auftreten abhängig ist (Einbrüche finden in der Nähe vorheriger Einbrüche statt). Stattdessen werden Straftate in Verbindung gesetzt mit Eigenschaften des Ortes sowie der sozio-demographischen Struktur dort. Zu diesen Rahmenbedingungen kann so ziemlich alles zählen von der Dichte an Kneipen bis zum durchschnittlichen Bildungsstand der Bewohner_innen eines Viertels. Das vorherige Auftreten von Straftaten kann beim RTM als ein Ebene berücksichtigt werden, muss es aber nicht.
In einem Kompendium ((J. M. Caplan und L. W. Kennedy, Risk Terrain Modeling Compendium: For Crime Analysis. New Jersey: Rutgers Center on Public Security, 2011.)) haben die Entwickler_innen eine ansehnliche Anzahl von Quellen zusammen getragen, die eine jeweiligen Straftatstype mit verschiedenen Eigenschaften (genannt Layer) eines Ortes in Verbindung bringen. Das führt zu recht ansehnlichen Abhängigkeiten, die mittels logistischer Regressionsanalysen berechnet werden. Diebstahl zum Beispiel passiert häufig in der Nähe von: öffentlichen Transportmitteln, Sehenswürdigkeiten, Restaurants und Bars, Shoppingmeilen, Parkplätzen, Fahrradabstellplätzen, Schulen, Hinterhöfen, Feldern, Spielplätzen, Verkaufsflächen und Läden für Helerwaren (RTM Compendium S. 51). Also eigentlich an fast allen öffentlich zugänglichen Orten.
Der in der deutschen predictive policing Debatte so wichtige Einbruchsdiebstahl findet laut Kompendium vor allem dort statt wo die social disorganization besonders hoch ist. (das beinhaltet: wenig informelle Überwachung, geringer sozioökonomischer Status der Bewohner_innen, hohe ethnische Durchmischung, hohe Fluktuation der Bewohner_innen), die Nähe zu Pfandhäusern ist genauso relevant wie die Entfernung zu öffentlichen Verkehrsmitteln und Polizeistationen. Zudem habe sich aus der Literatur ergeben, dass die Uhrzeit und der Wochentag wichtig sind (RTM Compendium S. 43)
Die Beispiele zeigen schon wie aufwendig die Datenaufbereitung beim RTM sein muss. Nicht nur das die Daten erst mal alle erhoben werden müssen, für den täglichen Einsatz, wie in HunchLab, müssen Sie auch regelmäßig aktualisiert werden.
Zur Effektivität dieser Methode gibt es wenig Informationen, vor allem wenig Praxiserfahrungen. Ich hab eine Studie ((G. Drawve, „A Metric Comparison of Predictive Hot Spot Techniques and RTM“, Justice Quarterly, Bd. 0, Nr. 0, S. 1–29, Apr. 2014.)) gefunden die RTM auf Basis einer Analyse historischer Daten von Raubüberfällen mit anderen Techniken vergleicht. Dabei zeigt sich, dass RTM in der Vorhersage zwar im Vergleich besser ist als andere Algorithmen (ohne einen absoluten Wert anzugeben), aber auch eine hohe Zahl false positives ausspuckt. Also Orte markiert die Gefährlich sind, ohne das dort etwas passiert worden wäre. Der Autor führt dies auf Tatsache zurück, dass beim RTM Orte mit gleichen Eigenschaften in den Layern eben als ähnlich riskobehaftet gesehen werden. Das mache aber bei einigen Tatsachen keinen Sinn. So würden zwar Bushaltestellen (die als Layer existieren) allgemein als gefährlich wahrgenommen, tatsächlich sei das Umfeld aber dabei ausschlaggebend. Das lässt eigentlich nur den Schluss zu, dass es eine noch genaueren Modellierung und damit Datenerhebung notwendig ist.
Daher heiß es auch bei Chainley/Tompson/Uhling (2008) ((S. Chainey, L. Tompson, und S. Uhlig, „The Utility of Hotspot Mapping for Predicting Spatial Patterns of Crime“, Secur J, Bd. 21, Nr. 1, S. 4–28, 2008.)) , dass es für jede Kriminalitätsart einen spezialisierte Algorithmus und Modellierung braucht.
Gefährliche Orte
Abseits der methodischen Datenkritik ist das Risk Terrain Modeling auch auf der konzeptionellen Ebene zu kritisieren. Es basiert auf der Annahme, dass Orte nur auf Grund ihrer Beschaffenheit als mehr oder weniger gefährlich wahrgenommen und polizeilich behandelt werden ist.
In Deutschland werden solche Bereiche auch als ‚gefährlich Orte‘ bezeichnet was in manchen Bundesländern eine rechtsgültige Definition ist, die der Polizei mehr Möglichkeiten zugesteht Personen zu kontrollieren. Die Einstufung eines Ortes als ‚gefährlichen Ort‘ geht allerdings über rein kriminologische Fragen hinaus.
„Erstens soll mittels räumlicher Maßnahmen tatsächliche oder vermeintliche Kriminalität an lokalen Konzentrationspunkten eingedämmt werden. Zweitens dient sie als Mittel der Aufwertung zentraler und besonders prestigeträchtiger städtischer Zonen oder so genannter ‚Visitenkarten‘. Drittens handelt es sich um ein Mittel der Durchsetzung antiliberaler Ordnungsvorstellungen und der Einhegung politischer Dissidenz oder subkultureller und sonstiger Abweichungen von der ‚Normalität‘.“ , Ullrich/Tullney (2012) sozialraum.de, Bd. 4, Nr. 2/2012.))
Der lesenswerte Artikel von Ullrich und Tullney und der dort eingangs zitierte Text von Belina/Wehrheim kritisieren, dass die polizeilichen Maßnahmen nur in einem Teil der Fälle tatsächlich der Bekämpfung von Kriminalität dienen. In vielen anderen Fällen sind sie Teil stadtpolitischer Maßnahmen sowie von Aufwertungs- und Verdrängungsprozessen; man erinnere sich an das alberne Beispiel des „Gefahregebiets“ in Hamburg im vergangenen Jahr.
HunchLabs Kooperationen
HunchLab nimmt natürlich nicht direkt Bezug auf diese Form der Nutzung, allerdings deutet die Zusammenarbeit mit Ralph Taylor (S. 5 des Dokuments), einem Forscher aus Philadelphia darauf hin, das nicht nur vermeintlich objektive Daten aus den Kriminalstatistiken für die Einstufung gefährlicher Orte genutzt werden können. Taylor hat einige Publikationen auf seiner Liste die sich mit der Wahrnehmung von Räumen durch Dritte als ‚gefährlich‘ beschäftigen. In einem seiner Artikel ((J. Covington und R. B. Taylor, „Fear of Crime in Urban Residential Neighborhoods: Implications of Between- and Within-Neighborhood Sources for Current Models“, The Sociological Quarterly, Bd. 32, Nr. 2, S. 231–249, Juli 1991.)) beschreibt er das Ergbnis einer Studie die ergab, dass Orte häufig als unsicher wahrgenommen werden, wenn dort auf die ein oder andere Art von gesellschaftlichen Normen abweicht. Diese Normen sind natürlich nicht zwangsläufig immer Dinge sind auf die man sich positiv beziehen sollten; in der Studie beschreibt er, dass (für die USA) solche Gegenden als nicht ’normal‘ wahrgenommen werden, in denen es keine Segregation (Trennung der Bewohner nach Ethnien) gibt. Auch solche Faktoren lassen sich in HunchLab berücksichtigen und das macht aus Sicht einer Polizei, zu deren Zielen es auch – vor allem in den USA – auch gehört ihre Akzeptanz und das Vertrauen zu erhöhen-
Auf der technischen Ebene kombiniert HunchLab die Near Repeat Theorie mit Risk Terrain Modeling und weiteren Methoden, vermutlich in der Hoffnung die algorithmischen Nachteile des einen mit den Vorteilen des anderen auszugleichen. Das bringt aber gleichzeitig die Gefahr mit sich, dass sich zu den konzeptionellen Probleme auch solche de Datenqualität gesellen, die auftauchen, wenn eine zunehmende Anzahl von Layer berücksichtigt werden sollen.
0 Kommentare
1 Pingback