Was man nicht alles aus Tweets vorhersagen kann. Wir hatten hier schon den Arbeitslosigkeit, Modetrends, und den Wunsch soziale Proteste zu erkennen bevor sie auf die Straße getragen werden. Kürzlich erschien eine weitere Studie, die nun nachweist, dass sich auch das Einkommen ((D. Preoţiuc-Pietro, S. Volkova, V. Lampos, Y. Bachrach, und N. Aletras, „Studying User Income through Language, Behaviour and Affect in Social Media“, PLoS ONE, Bd. 10, Nr. 9, S. e0138717, Sep. 2015.)) anhand der Tweets eines_r Users_in schätzen lässt.
Das Vorgehen ist in dem Fall ähnlich wie bei anderen Studien: Zuerst wird eine Beispielmenge (hier: 5000 Twitter-User_innen, die eine eindeutige Berufsbezeichnung in ihrem Profil genannt haben) mit einer sekundären Statistik annotiert (hier: Britische Durchschnittseinkommen für bestimmte Berufsgruppen). Dann werden die Daten mit weiteren Statistiken korreliert und geguckt anhand welcher Eigenschaften, die man eh schon aus einem Twitter-Profil heraus berechnen kann, man die neue Eigenschaft ‚vorhersagen‘ kann.
Interessant bei der Studie von Preoţiuc-Pietro u.a. ist, dass sie erst mal einen Haufen Eigenschaften aus den Tweets berechnet haben, deren Zuverlässigkeit bereits in anderen Studien getestet wurde. Darunter sind: Alter, Gender, politische Einstellung, Beziehungsstatus, Intelligenz, Religionszugehörigkeit und Einschätzungen von psychologischen Eigenschaften (siehe Bild).
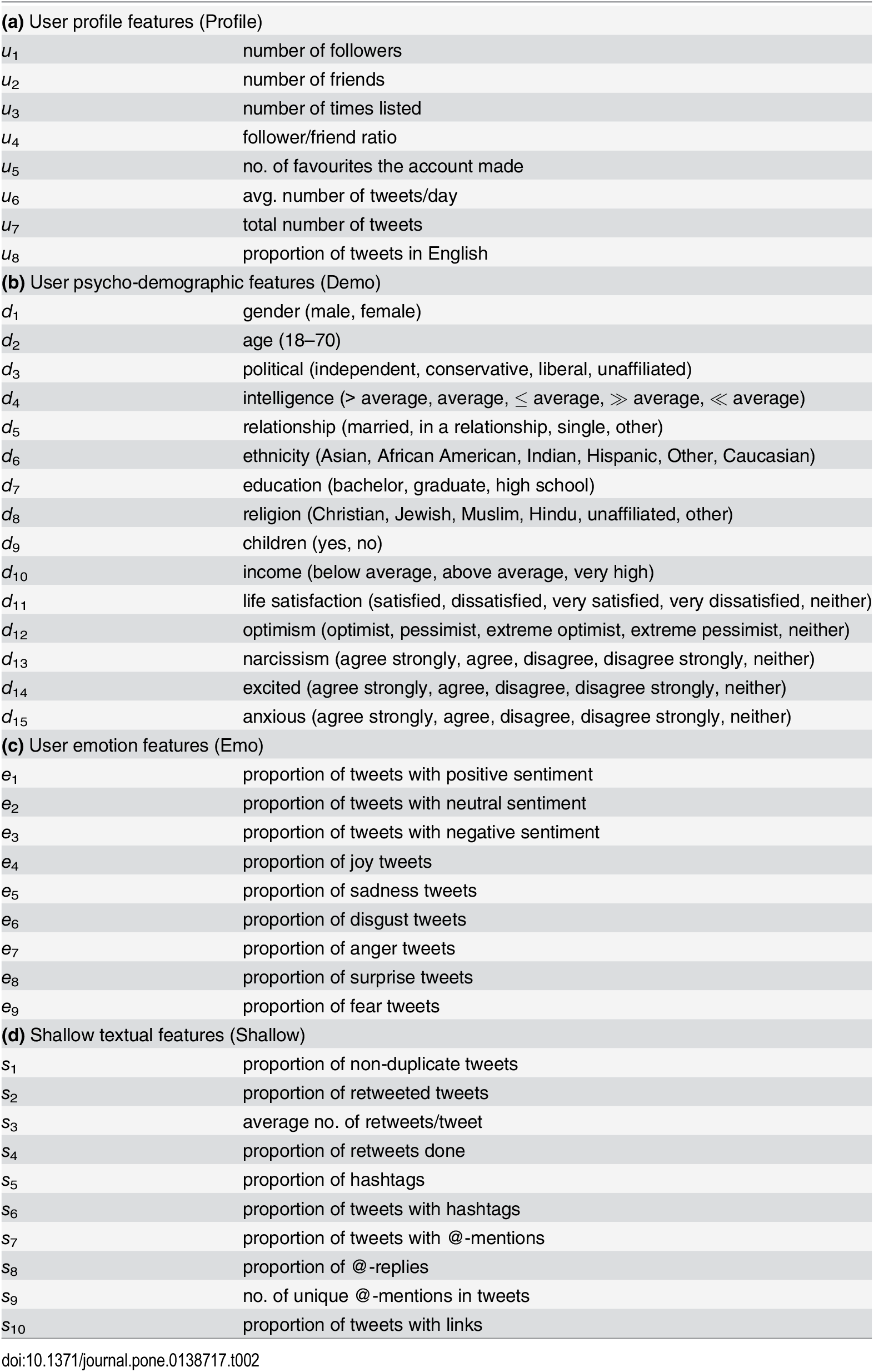
Liste der Eigenschaften die über ein Profil errechne und mit dem Einkommen in Verbindung gebracht wurden (Tabelle 2 der Studie)
Am Ende konnten die Forscher_innen anhand der kombinierten Zusammenhänge bei einer Korrelation von 0.6 etwas über das vermutlich Einkommen und die Eigenschaften berechnen. In ihren Ergebnissen konnten sie dann bekannte Abhängigkeiten wieder finden. So (wieder)entdeckten sie die finanzielle Gender Gap und das aus den USA bekannte Einkommensgefälle zwischen wahrgenommenen Ethnien. Neu sind die Erkenntnisse, dass Menschen die sich auf Twitter als Christen zu erkennen geben, weniger verdienen, reiche Leute weniger Tweeten aber mehr Follower haben, ärmere Twitteruser_innen mehr Fluchen und reiche dafür mehr Angst zeigen.
Potenzierte Ungenauigkeiten
Sicher sind die Daten ordentlich überprüft und alles statistisch valide. In der aggregierten Ansicht macht das alles auch einigermaßen Sinn. Die Frage ist, was passiert, wenn die vorgestellten Verfahren, wie von den Autor_innen vorgeschlagen, ihren Weg in die Praxis finden und auf die Profile von Einzelnen angewendet werden. Das ungefähre Einkommen einer Person zu kennen, ließe sich beim Dynamic Pricing sicherlich nutzen, etwa um den Preis für ein Produkt dem Geldbeutel anzupassen oder Werbung darauf auszurichten. Nur übernimmt man bei der vorgestellten Methode ziemlich viele Ungenauigkeiten, von denen in der Studie nur wenige diskutiert werden. Die Selbstausweisung von Berufen in Twitter ist alles andere als zuverlässig. Einkommensstrukturen sind extrem regional unterschiedlich, Datenbanken müssen eigentlich für jedes Land separat geführt werden, wie die Autor_innen aber selbst beschreiben, haben sie die Geolocation der Profile nicht berücksichtigen können. Und soweit ich das überblicke wird in der Studie von einem sehr statischen Identitätsmodell ausgegangen. Es werden zwar bis zu 3200 zurückreichende Tweets beobachtet, aber das erstellte Profil ist immer auf die Gegenwart bezogen. Ob sich das Profil über die Zeit (Twitter gibt’s nun auch bald 10 Jahre) vielleicht ändert, ist nicht Teil der Untersuchung. Das sich außerdem die Ungenauigkeiten etwa bei der Berechnung von Persönlichkeitsmerkmalen weiter übernommen werden und zu relativ wagen Zusammenhängen (eine Korrelation von 0.6 ist alles andere als eindeutig) führe, wird eigentlich gar nicht reflektiert. „Data sells“ auch ohne das.
Schreibe einen Kommentar